POSTS
Experiments part 9
Previously in Experiments, part 8,…
I got SSE working on the server-side and was happy about that.
Now…
Tonight, I’m going to hook that up to ReactJS. I am questioning how to do that, though. I know that I want to get, and then set the state of the root component. I wonder what ReactDOM.render returns. Does it return the actual component?
Time for an experiment
var component = ReactDOM.render(<LinkListContainer url="/api/links" />, document.getElementById("content"));
console.log(component);
Very simply, I am assigning the return value of ReactDOM.render to a variable and outputting that to the console. Thank $DEITY for browser consoles. Reloading the page and inspecting the Object returned shows me that it is the root component. Great, I love when software behaves how I think it should.
This makes things quite simple. I will pass the component into the EventSource callback function and do things.
evtSource.addEventListener("link-update", function(e) {
var currentData = component.state.data;
var replacement = JSON.parse(e.data);
var toReplace = currentData.filter(function(obj) {
if(obj.id === replacement.id) {
return obj;
}
})[0];
if(toReplace !== undefined) {
var idx = currentData.indexOf(toReplace);
currentData.splice(idx, 1, replacement);
component.setState({data: currentData});
}
});
The component gives me access to the data attribute holding the collection of links. The link-update event will send me a whole link record. Having those two things enables me to:
- Find the record that needs replacing, which is accomplished by matching ID fields.
- Splicing the new record into the position where the old one was.
- Updating the component with the new data using the standard
setStatecall.
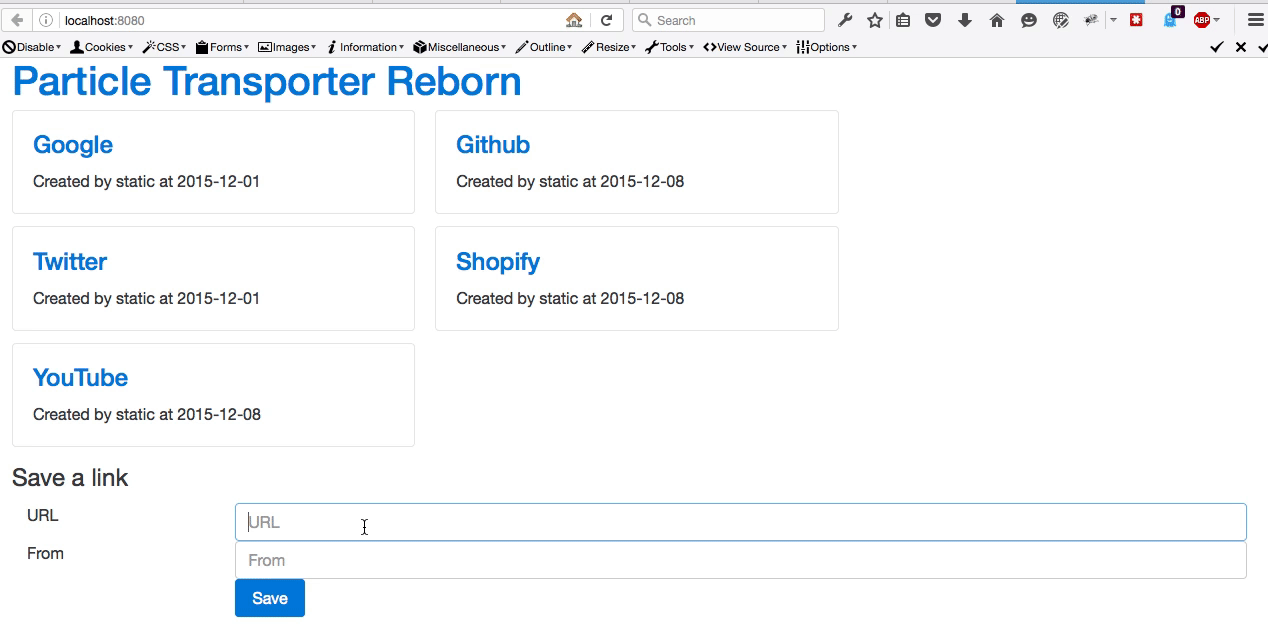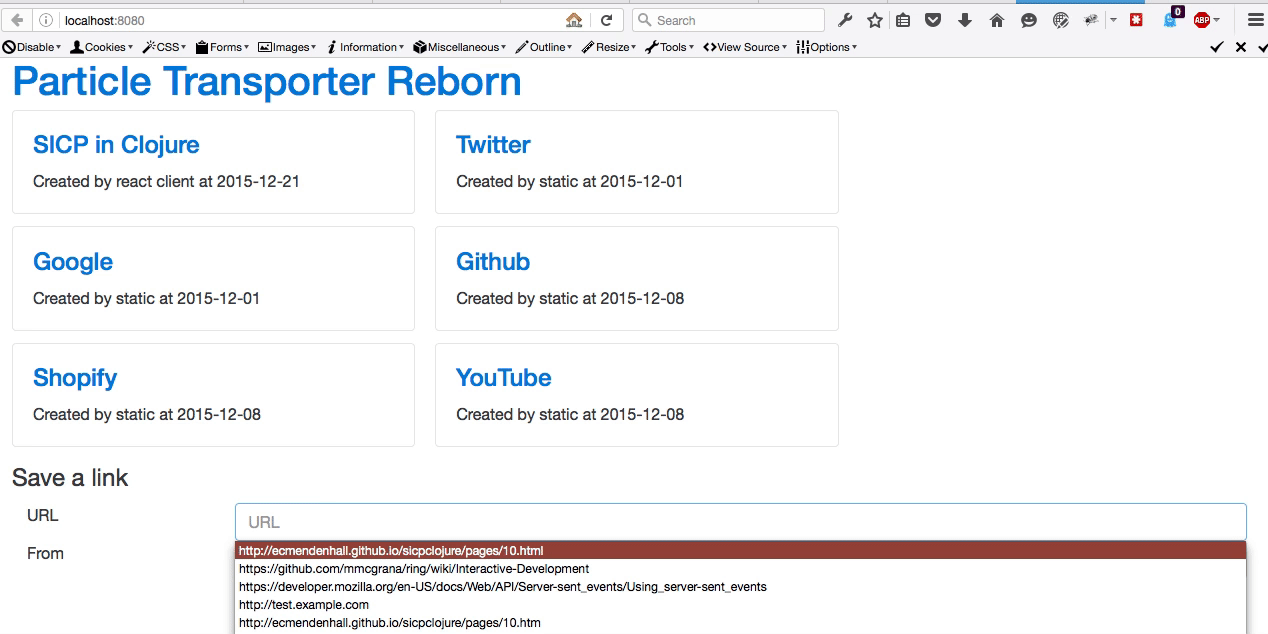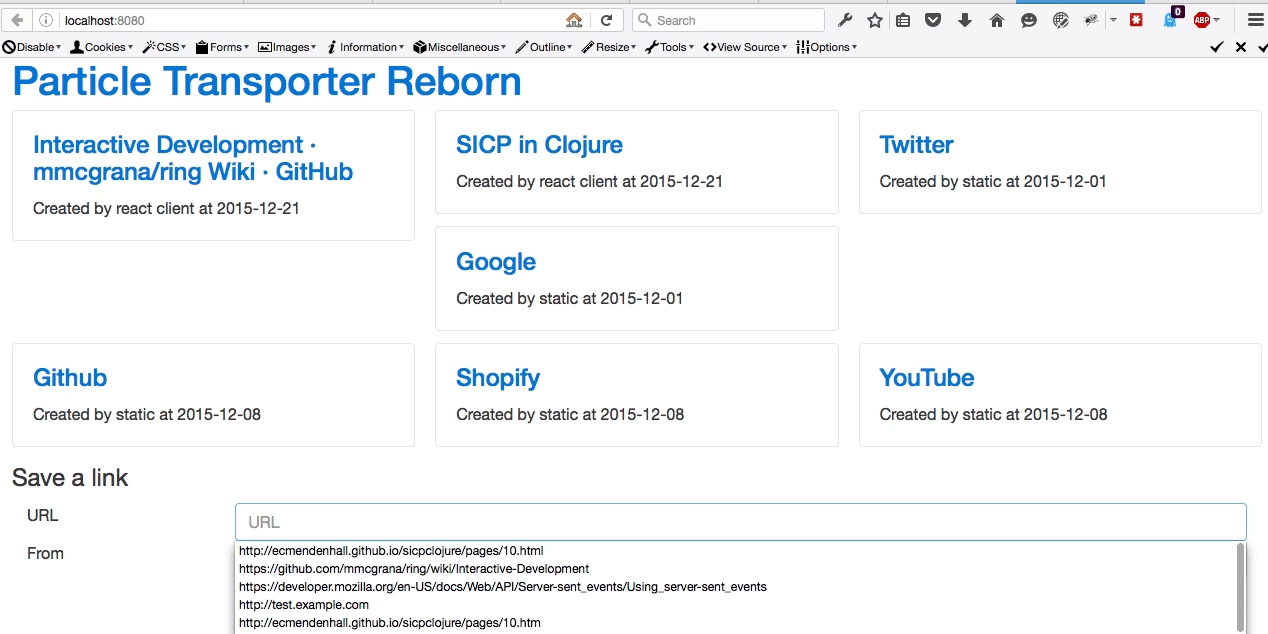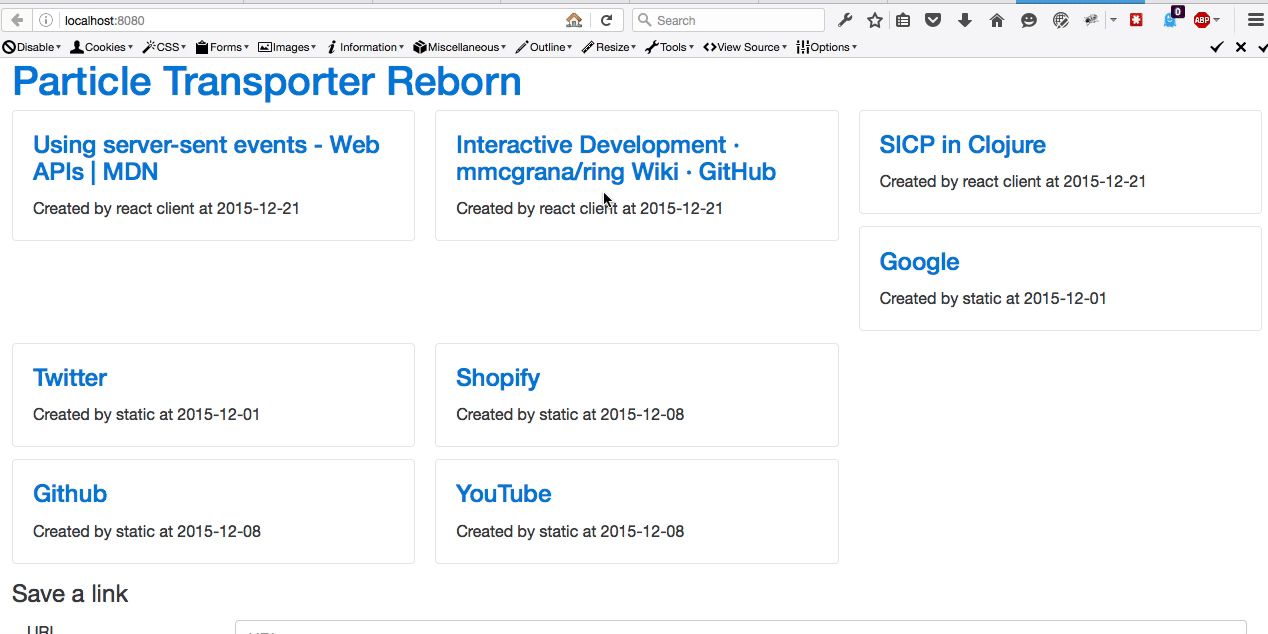
Simple and easy. I like that. Here is how that looks. Keep watching the top-left corner. You will see the initial value for the title being the URL, then see it change to the actual title.
What next
In some respects, this is now better than what I already have running. In others, it’s not there yet. There are few other things I’d like to add, though. Firstly, the title fetching code can only handle HTML pages, but I like to save links to PDFs, as well. I have a bit of working code somewhere that I’ll look to integrate. Secondly, I’d like to archive or delete the links I don’t want anymore. Thirdly, I will want to persist the in-memory collection to some data store and be able to retrieve it without modifying a lot.
Well, until the next blog post, good night.